
Python to już nie tylko „klej” do skryptów czy narzędzie dla data scientists. W nowoczesnym IT to fundament potężnych systemów backendowych i rozwiązań AI. Jednak pierwszy projekt komercyjny czy przejście z prostych skryptów do środowiska enterprise bywa bolesne. Wiele zespołów wpada w pułapki wydajnościowe (słynny GIL) lub architektoniczne, które po kilku miesiącach zamieniają projekt w trudne do utrzymania „spaghetti”. Jeśli chcesz uniknąć pułapek w Pythonie i dowiedz się, jak tworzyć oprogramowanie klasy enterprise, ten poradnik jest dla Ciebie. Przeanalizujemy listę 7 kluczowych aspektów oraz najczęściej popełnianych błędów, o które musisz zadbać, tworząc profesjonalne oprogramowanie. Jeśli interesuje Cię praktyczne wykorzystanie pythona do analizy, ten artykuł również pokryje te kwestie. Zrozumienie natury błędów w Pythonie to pierwszy krok do mistrzostwa.
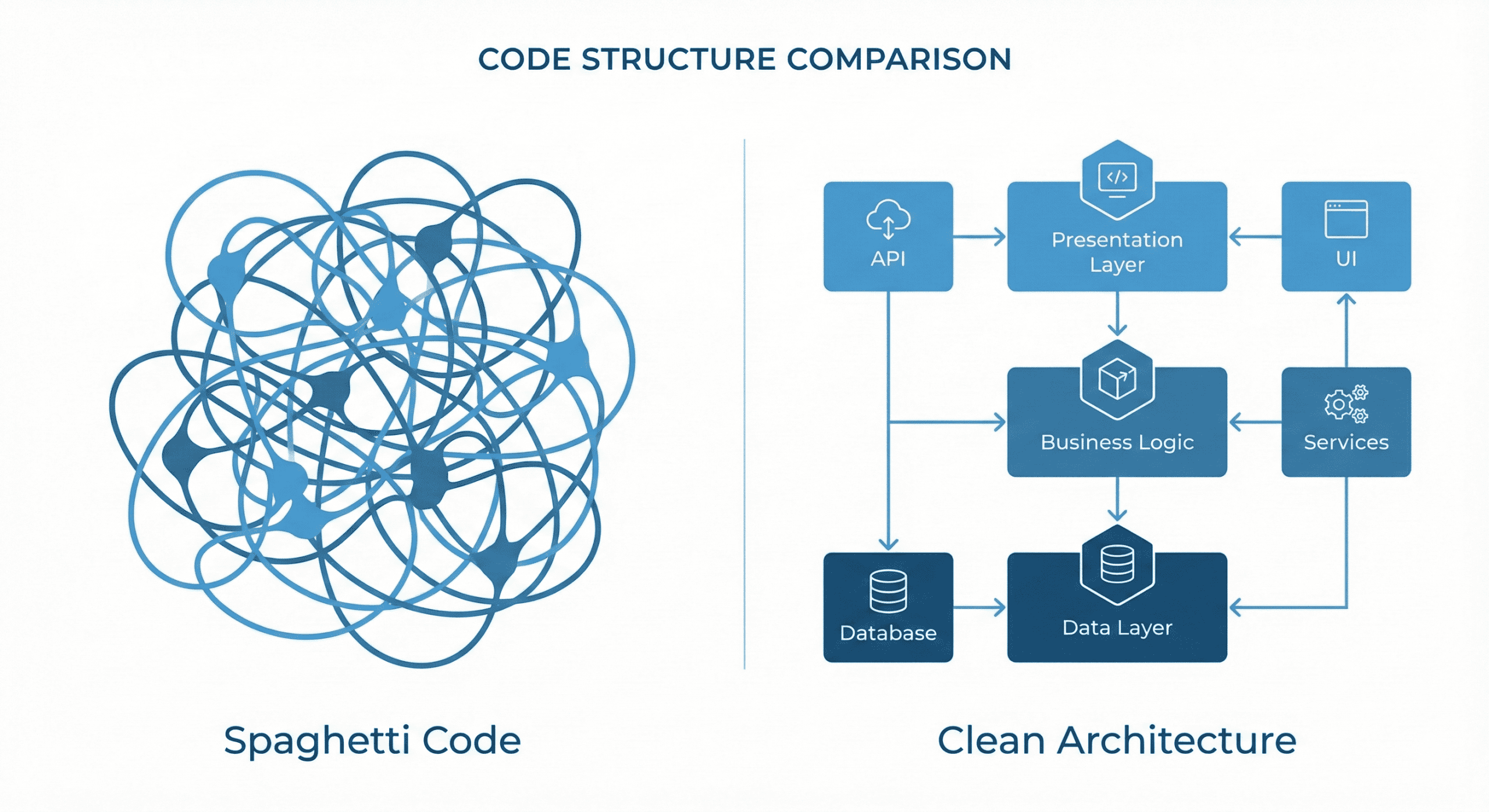
1. Ignorowanie architektury i zarządzanie projektem (spaghetti code vs czysta architektura)
Problem: Prostota Pythona bywa zwodnicza. Bez narzucenia sztywnych ram, kod szybko staje się chaotyczny, a logika biznesowa miesza się z frameworkiem. Właściwe zarządzanie strukturą projektu jest często pomijane na początku, co mści się w fazie utrzymania. Niewłaściwa organizacja kodu w pythonie prowadzi do trudnych do wykrycia problemów.
Rozwiązanie: W dużych projektach musisz wyjść poza standardowe struktury frameworków. Implementuj sprawdzone wzorce, takie jak DDD czy architektura heksagonalna. Pozwalają one odizolować logikę od warstwy danych. Pamiętaj, że kod w pythonie nie pisze się „na chwilę” – musi on być skalowalny. Aby programować efektywnie, należy dbać o jakość od pierwszych linijek kodu.
2. Błędy związane z typowaniem i niewłaściwe użycie zmiennych
Problem: „Python jest dynamiczny, więc nie potrzebuję typów”. To podejście w projekcie liczącym tysiące linijek kodu to przepis na katastrofę. Częstym problemem są błędy związane z niewłaściwym typem zmiennej, np. próba dodania int do float bez jawnej konwersji, co może generować nieoczekiwane wyniki lub `TypeError`. Równie groźne jest nieświadome nadpisywanie nazw wbudowanych, co sprawia, że użycie zmiennych staje się mylące (np. nadpisanie `list` lub `str`).
Rozwiązanie: Aby unikać typowych pomyłek, traktuj type hints (PEP 484) jako obowiązek. Wprowadź do potoku CI/CD statyczną analizę kodu (MyPy). Zdefiniowany type zmiennej to dokumentacja, która się nie przeterminowuje. Pamiętaj, aby nazwy zmiennych były opisowe, a typy danych zawsze kontrolowane.
# Źle (brak typów, niejasne nazwy):
def calc(a, b):
return a + b
# Dobrze (type hints i jasne nazwy):
def oblicz_sume_transakcji(kwota_netto: float, podatek: float) -> float:
return kwota_netto + podatek
3. Wybór narzędzi: Odpowiednia biblioteka i framework do zadania
Problem: Ręczne pisanie funkcjonalności, do których istnieje gotowa biblioteka. Wiele osób próbuje wbudować własne rozwiązania tam, gdzie standardowe narzędzia są wydajniejsze.
Rozwiązanie: Dobieraj technologię do problemu. Ekosystem Pythona jest ogromny.
- Budujesz CMS? Wybierz Django. Tworzysz API? Postaw na FastAPI.
- Chcesz przeprowadzić analizy danych i automatyzacji? Sprawdź, czy biblioteka Pandas nie zrobi tego szybciej.
- Do uczenia maszynowego standardem są Matplotlib i Scikit-learn.
4. Wydajność a przetwarzanie danych w Pythonie (GIL i async)
Problem: Nieefektywne przetwarzanie danych w pythonie. Przez blokadę GIL, Python używa jednego rdzenia. Próba zrównoleglenia obliczeń (CPU-bound) wątkami to jeden z najczęstszych błędów.
Rozwiązanie: Musisz rozumieć naturę zadania. Jeśli chcesz przetworzyć miliony rekordów danymi, użyj bibliotek C/C++ (NumPy). Jeśli zadanie czeka na sieć, użyj asynchroniczności. Pamiętaj, by poprawnie zdefiniować funkcje asynchroniczne (`async def`) i wywołać je przez `await`. Aby sprawdzić wydajność, używaj profilerów, a nie tylko `print`.
import asyncio
import httpx
# Prawidłowy kod asynchroniczny:
async def pobierz_dane_z_api(url: str):
async with httpx.AsyncClient() as client:
response = await client.get(url)
return response.json()
# Uruchomienie pętli zdarzeń:
# asyncio.run(pobierz_dane_z_api("https://api.przyklad.pl/dane"))
5. Wyjątek od reguły: Jak obsługiwać błąd składniowy i logiczny?
Problem: Zbyt szerokie klauzule `try…except`, które połykają każdy wyjątek, w tym nieoczekiwany błąd składniowy (np. w `eval`) czy `NameError` spowodowany zwykłą literówką. Zamiast profesjonalnego logowania, początkujący często używają instrukcji `print` do debugowania, co zaśmieca wyjście programu.
Rozwiązanie: Kod musi być poprawny i odporny. Stosuj dedykowane klasy wyjątków. Pamiętaj, że błąd składniowy (SyntaxError) zazwyczaj wyłapiesz na etapie parsowania, ale błędy logiczne wymagają obsługi. Czysty syntax, czytelny komunikat błędu i brak „gołych” exceptów to podstawa poprawności kodu. Unikaj też „magicznych” wartości, które trudno sprawdzić w trakcie debugowania.
# Źle (połykanie błędów):
try:
przetworz_dane(dane)
except:
print("Coś poszło nie tak")
# Dobrze (precyzyjna obsługa):
try:
przetworz_dane(dane)
except ValueError as e:
logger.error(f"Błąd walidacji danych: {e}")
except KeyError:
logger.warning("Brak wymagane klucza w słowniku")
6. Projekt analityczny: Walidacja danych, plik CSV i wizualizacja
Problem: Traktowanie projektu Data Science jako brudnopisu. Skrypty w Jupyter Notebook są nieczytelne, a dane ładowane bez weryfikacji. Częstym błędem jest ręczne parsowanie formatów takich jak plik CSV zamiast użycia dedykowanych narzędzi (Pandas), co prowadzi do błędów przy braku wartości (NaN) lub złym kodowaniu. Wykorzystanie pythona do analizy danych wymaga precyzji.
Rozwiązanie: Profesjonalna analiza wymaga inżynieryjnego podejścia.
- Walidacja danych: Zanim zaczniesz operować na danych w pythonie i danych wejściowych, sprawdź ich jakość (np. biblioteką Pandera). Monitoruj wszelkie zmian w danych.
- Praca z plikami: Wczytując plik (CSV, Excel), zawsze weryfikuj brakujące wartości.
- Wizualizacja: Dobry wykres jest kluczowy. Biblioteki takie jak Seaborn, Matplotlib czy Plotly pozwalają tworzyć zaawansowaną wizualizację. Pamiętaj, że wizualizacja to narzędzie diagnostyczne.
- NumPy i Pandas: To fundament. NumPy zapewnia wydajne operacje macierzowe, a Pandas (importowane jako `pd`) ułatwia manipulację tabelami.
import pandas as pd
# Bezpieczne wczytanie i sprawdzenie danych
try:
df = pd.read_csv('sprzedaz_2024.csv')
if df.isnull().values.any():
print("Uwaga: Znaleziono brakujące wartości (NaN) w pliku CSV!")
# Szybka analiza statystyczna
print(df.describe())
except FileNotFoundError:
print("Nie znaleziono pliku źródłowego.")
7. Najlepsze praktyki przy pisaniu kodu: Wcięcia i unikanie skrótów
Problem: Nieczytelny kod, niejasne nazwy (np. `x`, `temp`), brakujące wcięcia. W Pythonie, gdzie wcięcia definiują blok kodu, ich pomieszanie (tabulatory vs spacje) to klasyczny błąd składniowy (`IndentationError`). Innym błędem jest funkcja bez słowa kluczowego return (zwracająca domyślnie `None`), gdy oczekujemy wyniku, lub długa funkcja (tzw. „god object”) w jednym defa.
Rozwiązanie:
1. Najlepsze praktyki (PEP 8) są Twoim przyjacielem. Stosuj skróty myślowe ostrożnie – czytelność jest ważniejsza. Kod powinien być czytelny dla innych.
2. Zautomatyzuj styl przy pisaniu kodu. Wdróż lintery (Flake8), aby kod był zawsze prawidłowy.
3. Twoje IDE (np. PyCharm, VS Code) pomoże Ci sformatować kod i wykryć błędy w kodzie w czasie rzeczywistym.
# Context manager (with) - automatyczne zamykanie zasobów:
with open('logi.txt', 'a', encoding='utf-8') as plik:
plik.write("Nowy wpis w logu\n")
# Tutaj plik jest już bezpiecznie zamknięty, nawet w przypadku błędu.
Podsumowanie: Python jako lider wśród języków programowania
Programowanie w Pythonie na poziomie enterprise to sztuka balansu. Elastyczność języka Python pozwala na szybki start, ale skalowalność wymaga rygorystycznej dyscypliny i dbałości o niezawodność kodu od samego początku.
Spośród wielu języków programowania, Python wyróżnia się wszechstronnością. Unikając błędów w języku python (takich jak błędy wykonania czy problemy z pamięcią) i stosując nowoczesne metody (asyncio, CI/CD, testowanie), jesteś w stanie prowadzić udany projekt. Pamiętaj, że poprawny i prawidłowy kod to taki, który jest zrozumiały. Jeśli dopiero zaczynasz, sprawdź kurs python dla zaawansowanych, aby programować świadomie.
Szukasz platformy skrojonej pod Twoje potrzeby?
Skontaktuj się z nami poprzez formularz kontaktowy, a opowiemy Ci o szczegółach!